Contents

Fine-tuning LLMs with LoRA: A Gentle Introduction
| |
|
Four million dollars. That’s how much it cost to train GPT-3. Luckily, a new training technique called LoRA makes it possible to train LLMs for a very small fraction of the cost.
In this article, we’re going to experiment with LoRA and fine-tune Llama Alpaca using commercial hardware.
What is the difference between the LLaMA LLM and Alpaca?
First, we’ll quickly review some LLM genealogy. Llama is a large language model released by Meta. It’s Meta’s response to OpenAI’s GPT4, and is widely-considered to outperform GPT3.5.
Following the success of Llama, a research lab at Stanford released a new model called Alpaca, which was fine-tuned from the initial Llama model.
Alpaca is cheap to train, and performs on-par with OpenAI’s text-davinci-003. The initial Alpaca model was trained on 8 80GB A100s, and took 3 hours.
How was the LLaMA Alpaca LLM fine-tuned?
Fine-tuning involves taking an existing pre-trained model and training a small subset of parameters on new data. In order to fine-tune Llama, the Stanford Researchers used Open AI’s text-davinci-003 to generate 52K instructions. The instructions were passed into the model using Huggingface training library.
Models with billions of parameters are extremely expensive to fine-tune. Earlier this year, Microsoft introduced a new technique called LoRA, or Low-Rank Adaptation.
LoRA uses 10,000 fewer training parameters than GPT-3 and 3x less GPU memory, yet performs equal or better than GPT-3. Importantly, LoRA models introduce no additional latency per request, making it a contender for production-grade use-cases.
LoRA can be used on pre-trained models, by freezing the weights of the model and adding specific training layers to each transformer block in the model.
After the model is fine-tuned on the new dataset, the product of the matrices between the new model and the original model are combined, which allows the fine-tuned model to remain the same size as the original.
How to setup a training script to fine-tune LLaMA Alpaca
In this article, I’ll be using the following resources:
- Llama 2 Alpaca LoRA repo for the fine-tuning code
- Huggingface for the dataset used for fine-tuning
- beam.cloud for cloud GPUs and tooling to train and deploy the models
We’re going to train an instruction-following LLM on 52k rows of data generated by GPT-4.
I’m using the Instruction Tuning with GPT-4 dataset, which is hosted on Huggingface.
High-level Goal
- Implement the code in Llama LoRA repo in a script we can run locally
- Pass in the fine-tuning dataset to the model
- Setup a cloud GPU to run the fine-tuning process
- (Optional) Deploy an inference API to make predictions with the fine-tuned model
Training Script
The first thing we’ll do is setup the compute environment to run Llama 2.
We’ll run the training process on cloud GPUs from beam.cloud. The training script is run on a 24Gi A10G GPU:
| |
|
from math import ceil
from beam import App, Runtime, Image, Volume
from datasets import load_dataset
# Setup compute environment
app = App(
"fine-tune-llama",
runtime=Runtime(
cpu=4,
memory="32Gi",
gpu="A10G",
image=Image(
python_version="python3.10",
python_packages="requirements.txt",
),
),
# Mount Volumes for fine-tuned models and cached model weights
volumes=[
Volume(name="checkpoints", path="./checkpoints"),
Volume(name="pretrained-models", path="./pretrained-models"),
],
)
# Training entry point
@app.run()
def train_model():
# Trained models will be saved to this path
beam_volume_path = "./checkpoints"
# Load vicgalle/alpaca-gpt4 dataset hosted on Huggingface:
dataset = load_dataset("vicgalle/alpaca-gpt4")
# Adjust the training loop based on the size of the dataset
samples = len(dataset["train"])
val_set_size = ceil(0.1 * samples)
train(
base_model=base_model,
val_set_size=val_set_size,
data=dataset,
output_dir=beam_volume_path,
)
In order to run this on Beam, we use the beam run command:
beam run app.py:train_model
When we run this command, the training function will run on Beam’s cloud, and we’ll see the progress of the training process streamed to our terminal:
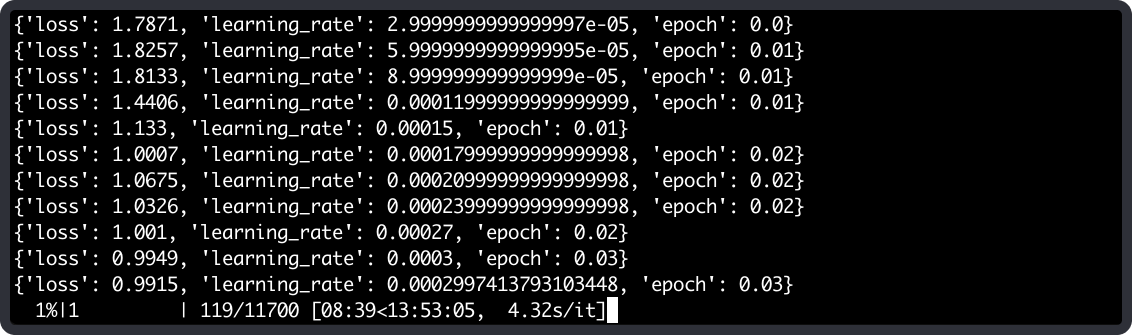
Deploying an Inference API
When the model is trained, we can deploy an API to run inference on our fine-tuned model.
Let’s create a new function for inference. If you look closely, you’ll notice that we’re using a different decorator this time: rest_api instead of run.
This will allow us to deploy the function as a REST API.
@app.rest_api()
def run_inference(**inputs):
# Inputs passed to the API
input = inputs["input"]
# Grab the latest checkpoint
checkpoint = get_newest_checkpoint()
# Initialize models with latest fine-tuned checkpoint
models = load_models(checkpoint=checkpoint)
model = models["model"]
tokenizer = models["tokenizer"]
prompter = models["prompter"]
# Generate text response
response = call_model(
input=input, model=model, tokenizer=tokenizer, prompter=prompter
)
return response
We can deploy this as a REST API by running this command:
beam deploy app.py:run_inference
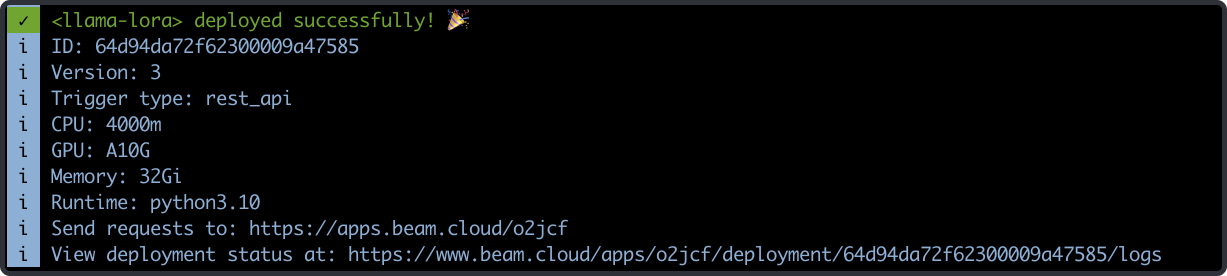
If we navigate to the URL printed in the shell, we’ll be able to copy the full cURL request to call the REST API.
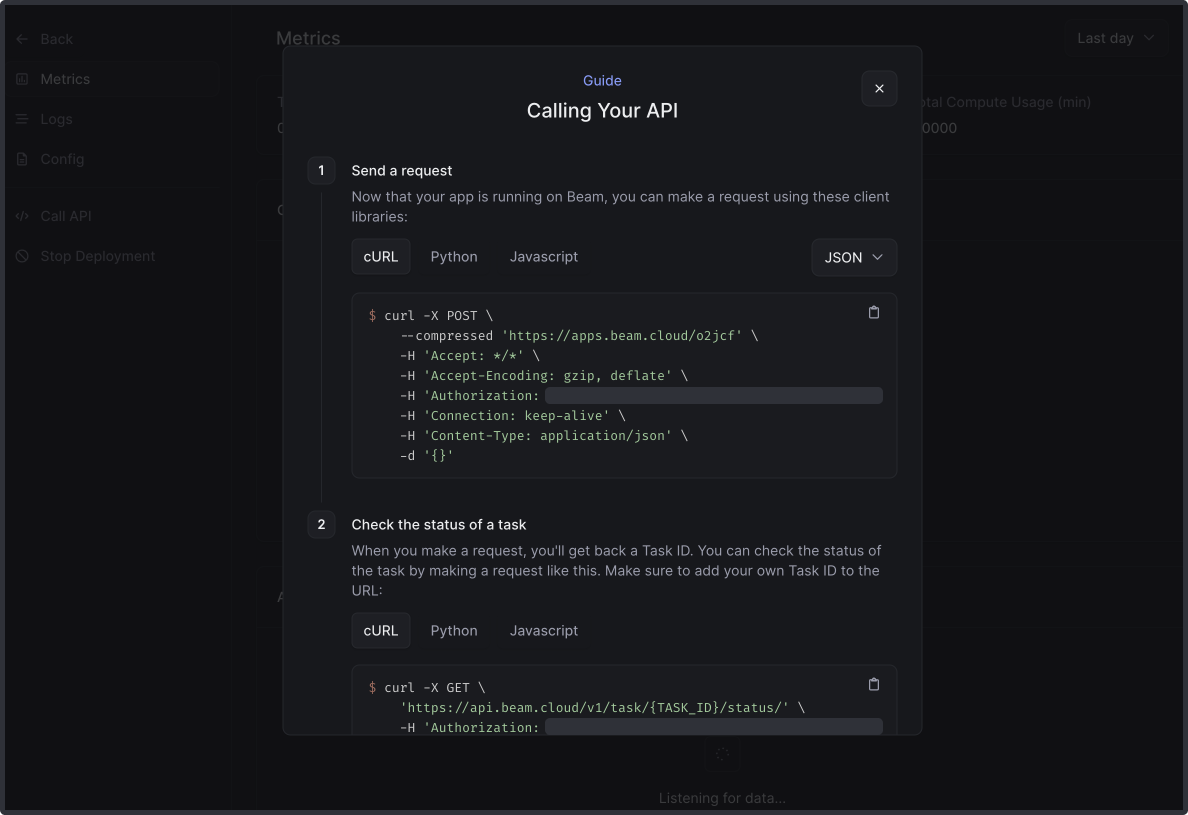
I modified the request slightly with a payload for the model:
-d '{"input": "what are the five steps to become a published author?"}'
And here’s the response from the fine-tuned model:
1. Create your manuscript with consistent writing sessions.
2. Revise and polish your work for clarity and accuracy.
3. Study your target audience and market trends.
4. Choose between traditional or self-publishing based on your goals.
5. Pursue traditional publishing with a compelling proposal.
Conclusion
Fine-tuning is a powerful technique for developing LLMs that perform relevant inference on your own dataset. With the addition of LoRA, anyone with access to a basic GPU can produce their own powerful and accurate LLMs.
The cloud GPU landscape is evolving too, and vendors like Beam, Banana, and Replicate offer pay-per-use GPUs that make it extremely affordable to fine-tune your own version of Alpaca.
Moreover, this post only scratches the surface of what’s possible from a model optimization standpoint. In order to optimize your fine-tuned Llama model in production, techniques like GPTQ and 4-bit quantization can be used to achieve superior inference speed without any drop in performance.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
