Contents
- Introduction to Streaming Frameworks
- Introduction
- Real-Time vs Micro-Batch Processing
- Choosing a Streaming Framework
- Apache Spark, Flink and Kafka
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/9792/0*lJX5ec98FLZdRel4)
Introduction to Streaming Frameworks
Understanding some of the key characteristics to consider when evaluating and comparing streaming technologies.
Introduction
As data architectures are becoming more and more mature, streaming is no longer considered a luxury but a technology with a wide range of applications across different industries. Because of technical and resource limitations, batch processing was in fact always the preferred way to process and deliver applications, although with the development of micro-batch and native streaming frameworks in distributed systems based on Apache, high-scale streaming has now become much more accessible (Figure 1).
Some example applications for using streaming systems, can be processing: transaction data to spot anomalies, weather data, IoT data from remote locations, geo-location tracking, etc.
Figure 1: Batch vs Streaming (Image by Author).
Real-Time vs Micro-Batch Processing
There are two key types of streaming processing systems: micro-batch and real-time:
In real-time streaming processing, each record is processed as soon as it becomes available. This can therefore result in systems with a very low latency, ready to make immediate use of the incoming data (e.g. detecting fraudulent transactions in financial systems).
In micro-batch processing systems, data points are instead not processed one by one but in small blocks and then returned after specific time intervals or once reached a maximum storage size. This type of approach favors therefore high throughput over low latency. Finally, micro-batch systems can be particularly useful if interested in performing complex operations such as aggregates (e.g. min, max, mean), joins, etc… on the fly before outputting the results in a storage system. Micro batch processing can therefore be considered a very good compromise between pure streaming and batch when performing for example hourly reporting tasks (e.g. mean weather temperature, etc.).
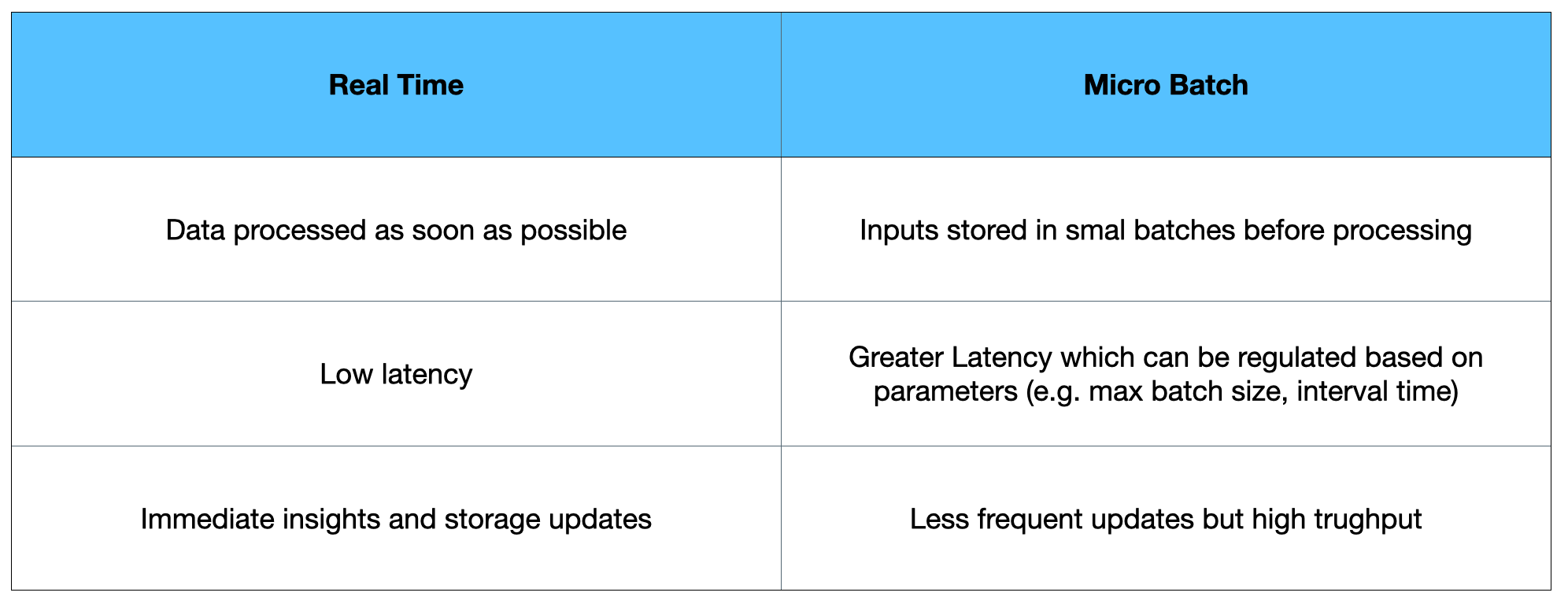
Figure 2: Real Time vs Micro Batch processing (Image by Author).
Choosing a Streaming Framework
Now that we have clarified the difference between micro-batch and real-time streaming processing, we are ready to examine some of the key points to keep into account:
Latency
Throughput
Memory Usage
Scalability
Fault recovery
Message Delivery Guarantees
Latency
Latency can be defined as the time taken for a task to process one or more inputs and return an output (how long it takes for streaming records to be processed once they entered our system). If low latency is a primary constraint, streaming frameworks would then be our best choice. In micro-batch processing, inputs are in fact buffered before being consumed (therefore increasing lag time).
Throughput
Throughput represents the aggregated rate of output data returned by our system. This can for example be represented by the amount of input data processed per second. For example, Apache Spark can use micro batch processing and by buffering the input data can be able to achieve high throughput rates. On the other hand, native streaming frameworks would then register lower throughput rates in order to optimize latency scores as much as possible.
Memory Usage
As streaming frameworks process lots of data every day, optimizing memory usage can be a very important factor in order to ensure the system would not get overwhelmed under heavy loads. Depending on the system architecture, these systems can in fact be designed to retain data for different amounts of time and if the data is either held for too long or large amounts are received all at the same time, then memory can become a big constraint. Evaluating memory usage optimization across different frameworks can therefore be a quite complicated task and highly dependent on the specifics of the project you might be working on. In this case, creating usage benchmarks with different examples of incoming loads could provide valuable insights in order to make a decision.
Scalability
In parallel processing streaming frameworks, scalability can be represented by the system’s ability to handle increasing amounts of work and evenly distribute jobs across the different working nodes available. This can for example be done by implementing a master-worker architecture, with master nodes designed to best plan task division between the worker nodes so that to avoid as much as possible to have worker nodes in idle while waiting for dependencies. Additionally, in highly scalable architectures, the system should automatically be able to understand when it is necessary or not to add/remove resources (e.g. worker nodes) in the cluster in order to respond to rising/declining workloads.
Fault Recovery
Another important consideration to keep into account is Fault recovery. This can in fact be defined as the ability of a system to be resilient and keep operating after the failure of one of its components. For example, if a worker node runs out of memory and is no longer functional, a new one should be automatically spun up in order to reduce downtime and it should be able to be able to pick up from a similar stage from where the other node left to not restart the whole process completely from scratch. When working with very large workloads in distributed systems, fault recovery represents a very important characteristic to keep in mind as failure might be more frequent than expected.
Message delivery guarantees
Finally, every streaming framework can offer different input delivery guarantees. Three of the most important delivery guarantees are:
Exactly once delivery
At most once delivery
At least once delivery
With Exactly once delivery, the system guarantees that every incoming input will be processed exactly once. With at most once instead, most of the inputs are expected to be processed but there is no warranty that an input will be processed if something goes wrong as part of the process. Ultimately, with at least once, every input is guaranteed to be processed and some messages might also end up being processed two or more times.
Two key criteria to keep in mind when choosing a message delivery method are: latency and computing costs. For example, exactly once would probably be the best choice from an accuracy point of view in most use cases, although this approach can easily add a lot of additional overhead costs (e.g. having a record history system to determine if an input was already processed or not and to recover in case of failure). Therefore, depending on the possible constraints for your application, other message delivery systems might provide more value for you.
Apache Spark, Flink and Kafka
Three of the most prominent Apache projects offering streaming capabilities are: Spark, Flink, and Kafka. Spark provides only micro batch processing, Flink both native streaming and batch, and Kafka just streaming.
Apache Spark is nowadays one of the most popular systems to run batch workloads and through its revamped Structured Streaming API is now gaining also more adoption for streaming tasks (with sub-second latency). Structured Streaming offers, in fact, an easier to use API, exactly once processing, built-in fault tolerance, and near real-time processing capabilities. If you are interested in learning more about Apache Spark, you can find more info about it in my introduction and optimization articles.
Apache Flink can support both infinite (stream) and finite (batch) streams. On the contrary to Spark though, by default, the runtime is streaming instead of batch. Moreover, Flink is also able to perform stateful computations (taking advantage of data dependencies across time to perform aggregations, joins, etc.).
Finally, Apache Kafka is a specialized platform designed to perform streaming operations. It started in 2011 as a messaging queue system and is now a complete streaming framework with built in support for both computing and storage. Apache Kafka is composed of 4 key APIs: Kafka Streams, Producer, Consumer, and Connector. Using the Kafka Streams API can provide many advantages such as: out of the box great scalability, cluster management, automatic failover, etc…
Additionally, if needed, different frameworks can also be used together in the same system in order to make the most of their best capabilities (e.g. using Kafka for streaming Storage and Flink for Computations).
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
