Contents
- Supercharging Your Machine Learning Models with Data Augmentation
- Data Augmentation: What is it, again?
- Data Augmentation: When Do We Need It?
- Data Augmentation vs. Preprocessing: Know The Difference?
- Data Augmentation: Examples
- Data Augmentation Techniques
- Advantages of Data Augmentation
- Disadvantages of Data Augmentation
- How to Implement Data Augmentation
- Data Augmentation: Final Thoughts
:format(webp))
Supercharging Your Machine Learning Models with Data Augmentation
| |
|
Get ready to explore ins and outs of data augmentation, including its definition, benefits, limitations and different techniques for data augmentation.
Data Augmentation: What is it, again?
When stuck with a Machine Learning solution unable to perform with a good level of accuracy, it can be quite tempting to consider the model as the problem. Therefore trying to replace it with more and more complicated approaches in the hope of increasing performance. In many situations, though, the solution can be found in the data that is actually fed into these models.
Data Augmentation is the art of artificially creating new training data by cleverly modifying existing samples. This can be done by either using subject matter domain expertise or using Deep Learning to generate modified samples.
For example, our input data might not provide as much variation as the actual real-world data distribution. Adding some artificial variations could therefore result in much more robust ML models. In addition to this, also the use of rigorous preprocessing techniques such as Feature Engineering, Feature Extraction, and Feature Selection could greatly improve the quality of the data fed into our models. Feature Selection reduces the number of features used to train a model by selecting only the most relevant ones. Feature Extraction techniques (e.g., PCA, LDA, etc.) aims at summarizing multiple features into a smaller subset. Feature Engineering finally encompasses many different approaches which can be taken to improve the quality of the features we are provided to make it easier for ML models to extract knowledge from them.
Typically, to achieve the best performance, you’d want to mix data augmentation with high-quality data labeling, with each of these techniques critically contributing to the overall performance and reliability of your machine-learning models. Data labeling provides the necessary ground truth annotations for supervised learning, enabling models to recognize patterns and make accurate predictions. This ensures that models generalize well, reducing the risk of overfitting and improving performance on unseen data. Properly augmented data enhances the robustness and diversity of the labeled dataset by creating new training samples through various transformations. This process artificially increases the size of the dataset, reducing overfitting and helping models generalize better, especially when the original dataset is small or unbalanced. Finally, data augmentation exposes the model to a wider range of variations and conditions, simulating real-world scenarios and improving the model’s overall performance and adaptability.
It is important to note that Data Augmentation is a different concept from Synthetic Data Generation. In Synthetic Data Generation, data is in fact, generated without using the original data as a base (and can therefore result in more varied and unexpected results). For example, Synthetic data can be created using adversarial training techniques such as GANs (Generative Adversarial Networks) or using Neural Style Transfer. GANs are constituted by 2 different submodels: a generator and a discriminator. The generator is trained to create new images as realistically as possible, while the discriminator’s goal is to be able to correctly distinguish original images from the ones created by the generator. In Neural Style Transfer, instead, we provide a model with 2 images (a content image and a style reference image). The network will then blend the two and generate an output image with the style of the reference image infused on the content image.
Data Augmentation: When Do We Need It?
Some of the main benefits of using Data Augmentation can be:
- Expanding the training dataset if not enough data is provided.
- Increase our model performance in production by providing more variety of training data.
- Since new data can be artificially created, no additional manual labeling and preprocessing is needed.
- To reduce the likelihood of overfitting.
- To emphasize some properties for our model to learn (e.g., making it invariant to rotation, translation, dialects, etc.).
Data Augmentation vs. Preprocessing: Know The Difference?
Unlike preprocessing, which focuses on retrieving raw data and structuring it in the best way possible to facilitate learning, Data Augmentation aims mainly at complementing the existing data with some variations of it which are at the current state under-represented compared to the real-world proportions.
For example, during data preprocessing, we might ensure the data we are provided with is: complete (e.g., no missing values), doesn’t have any anomalies (e.g., out-of-range values), does not contain duplicated information, is consistent with the units of measurement used, etc.
Data Augmentation: Examples
Data Augmentation can be applied to various data types (e.g., Image, Text, Audio, Video) and for different commercial applications.
For instance, it can be quite costly to gather image and video data to train self-driving cars for each possible scenario (e.g., urban/rural, driving on the left/right, night/day, and different types of street signage). Another example could be to create realistic images of rare pathologies for medical applications (e.g., different forms of cancer, retinal disease, and pneumonia). In this case, image augmentation can be of great help to resolve unbalanced classification problems and reduce the gap between classes that are easy to record and others that might be more difficult to find.
What is Data Augmentation in CNN?
CNNs (Convolutional Neural Networks) are a type of Deep Learning model particularly well-suited to work with image data, although not able on its own to robustly recognize the same image if it has been rotated or altered compared to the original one (unless provided with many variations directly in the training data). Therefore a popular application of Data Augmentation is to make CNN models invariant to different types of image transformations (e.g., rotation, translation, flipping, cropping, etc.).
Data Augmentation Techniques
Image Data Augmentation Techniques
Some examples of Image Data Augmentation Techniques can be:
- Geometric Transformations: zooming, stretching, cropping, flipping, rotating, resizing.
- Kernel Filtering Operations: applying mathematical filtering operations to alter the blurring and resolution of the images.
- Blending of different Images.
- Color Space Alteration: adjust the parameters of the color space in use. Most commonly, RGB (Red, Green, Blue) or HSV (Hue, Saturation, Value).
Text Data Augmentation Techniques
Some examples of Text Data Augmentation Techniques can be:
- Replacing words with synonymous using lookup tables.
- Adding/removing words at random.
- Shuffling the order of words in a phrase.
- Translating between languages.
- Using contextual word embeddings (replacing a word with another one that is as close as possible to it in a word embedding representation such as Glove, Word2Vec, etc.).
- Using pre-trained models (e.g., Transformers) to replace words while keeping the whole sentence context.
Audio Data Augmentation Techniques
Some examples of Audio Data Augmentation Techniques can be:
- Altering the speed/pitch of the clips.
- Shifting the recording either back or forward of a few seconds.
- Adding random/gaussian noise to the audio sample.
Video Data Augmentation Techniques
Some examples of Video Data Augmentation Techniques can be:
- Image Augmentation based techniques.
- Simulation techniques to bridge frames.
- Temporal transformations: upsampling, downsampling, etc.
Advantages of Data Augmentation
Using Data Augmentation to train our ML models on a more varied input set can then lead to the following advantages:
- Increased accuracy of machine learning models.
- Reduction in overfitting.
- Improving the generalization capability of the model.
- Less initial data is required to build models (e.g., data collection and labeling become less costly).
- Enhancing data quality (e.g., if in a classification problem, a class is under-represented, we can use data augmentation to reduce the gap).
Disadvantages of Data Augmentation
On the other hand, using Data Augmentation can also have its drawbacks:
- Time-consuming and computationally expensive: Different augmentation techniques can in fact have input parameters that require some tuning and which could also slow down the training process.
- May result in the loss of some information (e.g., operations such as cropping, zooming, etc.).
- Can result in the generation of unrealistic data (if the augmented data is generated without supervision).
- If bias is present in the original dataset, data augmentation could amplify its effects.
How to Implement Data Augmentation
To facilitate the adoption of Data Augmentation, throughout the years, different libraries have been developed in Python. Some examples are:
- Albumentations: is a stand-alone open-source Python Image Data Augmentation library. Albumentations has been designed to be extremely performant and to provide an easy-to-use API interface that can integrate out of the box with other Deep Learning frameworks such as Tensorflow and PyTorch. Albumentations can work on different types of image data such as RGB/grayscale images, key points, bounding boxes, etc.
- NLPAug: is an open-source Python NLP (Natural Language Processing) Data Augmentation library designed to generate synthetic text and audio data. NLPAug can be easily integrated in other ML/DL workflows (e.g., scikit-learn, Tensorflow, PyTorch).
- Tensorflow/Keras: Tensorflow and Keras provide different forms of interfaces to perform data augmentation tasks such as: keras.Sequential, ImageDataGenerator and tf.image.
- PyTorch Torchvision: using the torchvision.transforms module, it can also be possible to execute data augmentation tasks in PyTorch during the model pre-processing stage.
Additionally, it can always be possible to create ad-hoc transformations in plain Python to satisfy any specific use case your project might have.
Steps for Implementing Data Augmentation Techniques in a Machine Learning Pipeline
One key aspect to keep in mind to create robust ML projects is to make sure every step in your pipeline is reproducible. In fact, in a real-world environment, we would not have to go through the pipeline flow (Figure 1) just once but periodically retrain our model as new data becomes available and performance might degrade.
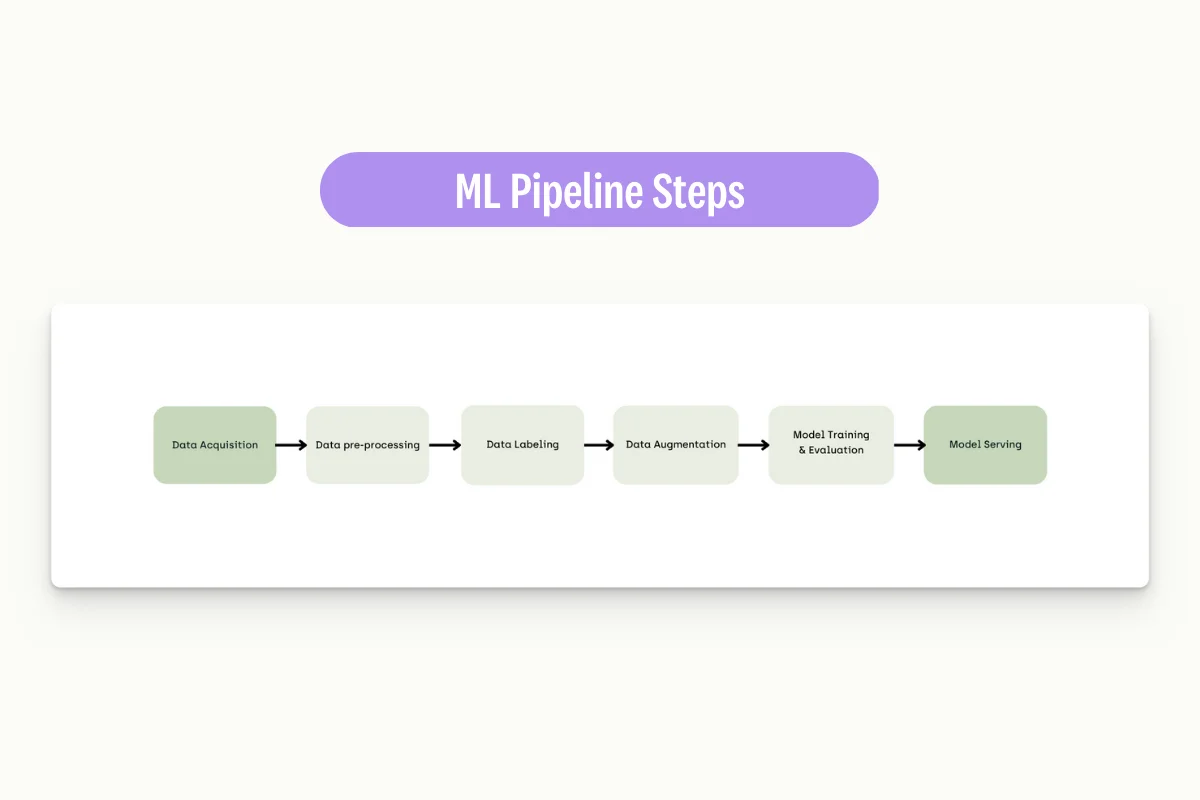
Figure 1: ML Pipeline Steps
Once we’ve labeled our data and defined consistent pre-processing steps, the data augmentation process can begin. As part of this step, we can then ensure the right variety and amount of data is generated to complement our existing training dataset for the ML model. For real-world applications, it might be then necessary to validate the augmented data with some subject matter experts to be sure the data fed in the rest of the pipeline is accurate and realistic. Finally, it is important to perform Data Augmentation just on the training dataset and not use augmented images from the validation data to avoid Data Leakage.
Practical Implementation
First of all we need to import all the necessary libraries.
from PIL import Image
import albumentations as A
import nlpaug.augmenter.word as naw
import numpy as np
import matplotlib.pyplot as plt
In order to show image augmentation capabilities, we can now load a starting image to augment
data = Image.open("example.png")
plt.imshow(data)
plt.savefig('original.png')
plt.show()

Figure 2: Original Image
At this point, we can just convert our image into an array format and apply a series of transformations (9 in total). As shown in the code snippet below, using Albumentations, we can either apply a single transformation to an image or, like in the last example also, a combination of transformations simultaneously. Finally, each of the different transformations comes with different parameters, which can be used to provide more control over the expected output. For example, when resizing/cropping an image, we can specify the expected width and height in pixels, or with probabilistic transformations, we can decide the likelihood with which a transformation should be applied.
image = np.array(data)
images = [data,
A.Resize(width=32, height=32)(image=image)['image'],
A.Blur(blur_limit=(100, 100), p=1)(image=image)['image'],
A.GaussNoise(var_limit=650.0, p=1.0)(image=image)['image'],
A.Rotate()(image=image)['image'],
A.Flip(p=1)(image=image)['image'],
A.ChannelShuffle(p=1)(image=image)['image'],
A.RandomGridShuffle(grid=(7, 7), p=1)(image=image)['image'],
A.Compose([
A.Resize(width=64, height=64),
A.CenterCrop(width=45, height=45)
])(image=image)['image']]
titles=["Original", "Resize", "Blur",
"Gaussian Noise", "Rotation", "Flip",
"Shuffling Channels", "Random Grid Shuffle",
"Resize + Crop"]
plt.figure(figsize=(9, 8), dpi=200)
for num, (img, title) in enumerate(zip(images, titles)):
plt.subplot(len(images)//3, len(images)//3, num+1)
plt.title(title)
plt.imshow(img)
plt.savefig('augmented.png')
As shown in Figure 3, we can then inspect the result of our transformations. It is important to remember that some of the transformations used are non deterministic and therefore running the same code multiple times in your own time might lead to different results.

Figure 3: Image Augmentation Results
We are now ready to start exploring how to perform Data Augmentation on text data. One of the simplest approaches we can take is to perform single-word replacements (without having any context of the sentence as a whole). This approach is commonly referred to as Character/Word Level Augmentation. It can be easily implemented in Python with data structures such as dictionaries to look up each word synonym/antonym or using word embeddings (e.g., GloVe, Word2Vec).
As a first attempt, we can try to replace 0.3% of the sentence with a synonym.
text = "It is prohibited to eat frozen yogurt on the way to work"
aug = naw.SynonymAug(aug_p=0.3)
aug.augment(text)
['Information technology is prohibited to run through frozen yoghourt on the room to work']
Another approach could be to replace words at random with their antonym (opposite).
aug = naw.AntonymAug(aug_p=0.5)
aug.augment(text)
['It differ permit to eat unfrozen yogurt on the way to idle']
Or to randomly change the order of words.
aug = naw.random.RandomWordAug(action='swap', aug_p=0.5)
aug.augment(text)
['Prohibited it is to frozen eat on way yogurt the to work']
Finally, it can also be quite useful to introduce spelling mistakes in our data. Spelling mistakes can in fact occur quite frequently in our daily life and therefore training our models on some of them can make it more flexible to not get confused between words just because of a spelling mistake.
aug = naw.SpellingAug(aug_p=0.5)
aug.augment(text)
['It 1s prohobited lo eight frozen yogurt on tht wat to work']
A more advanced approach to performing Data Augmentation on a word level would then be to use pre-trained Deep Learning models able to understand the context around a word to decide how to alter a sentence best. This approach is commonly referred to as Flow Augmentation. For this example, we can use Google BERT as our model of choice, although NLPAug, too, can provide a wide range of pre-trained models for you to pick.
aug = naw.ContextualWordEmbsAug(model_path='bert-base-uncased',
action="insert")
aug.augment(text)
['additionally it specifically is prohibited only to eat strictly frozen soy yogurt on the way to work']
To improve performance and make your augmentations look as natural as possible, there are a lot of different additional parameters which can be specified when using NLPAug. Some examples can be the language of the input data, the percentage of words to augment in a sentence, the minimum/maximum number of words to augment, listing the stopwords to not include in the augmentation process, etc.
Once we’ve completed the Data Augmentation process and integrated the new data in the training dataset, we can then continue as usual to train our models using frameworks such as PyTorch, TensorFlow, and scikit-learn.
Data Augmentation: Final Thoughts
To summarize, Data Augmentation can be a great asset in the toolkit of any Data Scientist. It can contribute to creating more performing and robust models. This has been widely recognized throughout the last few years by the development of many different libraries and products designed to make these operations more accessible to practitioners.
Additionally, it is important to remember that also other approaches exist to fine-tune the performance of a model, such as: optimizing the hyperparameters of your ML/DL model (e.g., fine-tuning layers, regularization options, rate schedules used for the gradient update, etc.), applying Transfer Learning, reducing overfitting, etc. (Figure 4). Each of these approaches would then be more or less suitable depending on your application and training data. Choosing the wrong approach could then result in more damage than anything else.

Figure 4: Understanding which fine-tuning approach to use
Data augmentation and data labeling are intrinsically intertwined processes, each critically contributing to the overall performance and reliability of machine learning models.
In essence, data labeling provides the foundational annotations required for effective supervised learning, while data augmentation bolsters the diversity and representativeness of the labeled dataset. These two processes work in tandem to optimize the training and performance of machine learning models, fostering their ability to make accurate predictions and generalize well across various scenarios.
For those seeking a seamless and efficient data annotation experience, exploring Kili Technology could be a game-changer. This data annotation platform boasts a user-friendly interface, collaborative features, and advanced automation capabilities, streamlining the labeling process and enhancing overall productivity. With Kili Technology, teams can benefit from a more efficient and accurate annotation process, ultimately leading to better model performance.
Resources on Data Augmentation
- Audiomentations: Open Source Python library for audio data augmentation.
- VidAug: Open Source Python library for video data augmentation.
- A survey on Image Data Augmentation for Deep Learning. Connor Shorten & Taghi M. Khoshgoftaar — Springeropen.
- Feature Engineering Techniques
- Feature Selection Techniques
- Feature Extraction Techniques
Courses
- Coursera — Image Data Augmentation with Keras
- Udemy — Data Augmentation in NLP
- Udemy — Convolution Neural Network with Data Augmentation
- NVIDIA Deep Learning Institute — Data Augmentation and Segmentation with Generative Networks for Medical Imaging
Ebooks
- Data augmentation and image understanding, PhD Thesis, Institute of Cognitive Science — University of Osnabruck
- Effective Techniques of the Use of Data Augmentation in Classification Tasks. Unai Garay Maestre.
- Smart Augmentation Learning an Optimal Data Augmentation Strategy. Joseph Lemley, Shabab Bazrafkan and Peter Corcoran.
- Research Trends and Applications of Data Augmentation Algorithms. Joao Fonseca and Fernando Bacao.
- A Novel Data Augmentation Technique for Out-of-Distribution Sample Detection using Compounded Corruptions. Ramya Hebbalaguppe, Soumya Suvra Ghosal, Jatin Prakash, Harshad Khadilkar and Chetan Arora.
- Data Augmentation, Labelling, and Imperfections. Second MICCAI Workshop, DALI 2022, Held in Conjunction with MICCAI 2022, Singapore, September 22, 2022, Proceedings.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
