Contents
Photo by Manuel Nägeli on Unsplash
Apache Spark Optimization Techniques
A review of some of the most common Spark performance problems and how to address them
Introduction
Apache Spark is currently one of the most popular big data technologies used in the industry, supported by companies such as Databricks and Palantir.
One of the key responsibilities of Data Engineers when using Spark, is to write highly optimized code in order to fully take advantage of Spark’s distributed computation capabilities (Figure 1).
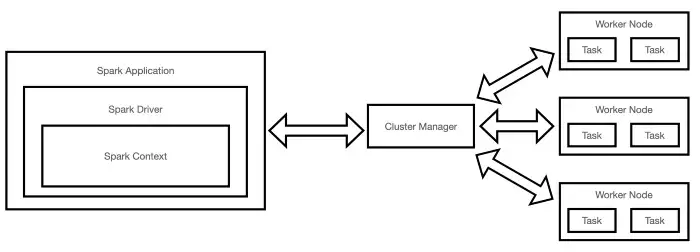
Figure 1: Apache Spark Architecture (Image by Author).
As part of this article, you are going to be introduced some of the most common performance problems when using Spark (e.g. the 5 Ss) and how to address them. If you are completely new to Apache Spark, you can find additional information about it in my previous article.
The 5 Ss
The 5 Ss (Spill, Skew, Shuffle, Storage, Serialization) are the 5 most common performance problems in Spark. Two key general approaches which can be used to increase Spark performance under any circumstances are:
- Reducing the amount of data ingested.
- Reducing the time Spark spends reading data (e.g. using Predicate Pushdown with Disk Partitioning/Z Order Clustering).
We will now dive into each of the problems associated with the 5 Ss.
Spill
Spill is caused by writing temporary files to disk when running out of memory (a partition is too big to fit in RAM). In this case, an RDD is first moved from RAM to disk and then back to RAM just to avoid Out Of Memory (OOM) errors. Disk reads and writes can although be quite expensive to compute and should therefore be avoided as much as possible.
Spill can be better understood when running Spark Jobs by examining the Spark UI for the Spill (Memory) and Spill (Disk) values.
- Spill (Memory): the size of data in memory for spilled partition.
- Spill (Disk): the size of data on the disk for the spilled partition.
Two possible approaches which can be used in order to mitigate spill are instantiating a cluster with more memory per worker or increasing the number of partitions (therefore making the existing partitions smaller).
Skew
When using Spark, data is commonly read in evenly distributed partitions of 128 MB. Applying different transformations to the data can then result in some partitions becoming much bigger or smaller than their average.
Skew is the result of the imbalance in size between the different partitions. Small amounts of Skew can be perfectly acceptable but in some circumstances, Skew can result in Spill and OOM errors.
Two possible approaches to reduce Skew are (Figure 2):
- Salting the skewed column with random numbers to redistribute partition sizes.
- Using Adaptive Query Execution (Spark 3).
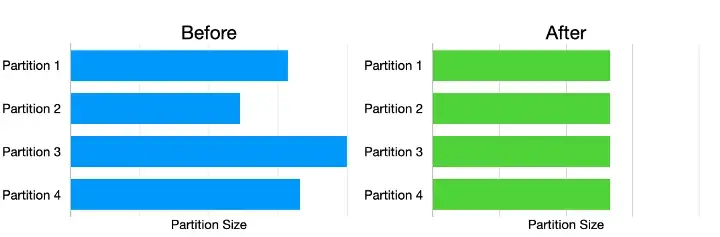
Figure 2: Partition Size Distribution Before and After Skew (Image by Author).
Shuffle
Shuffle results from moving data between executors when performing wide transformations (e.g. joins, groupBy, etc…) or some actions such as count (Figure 3). Mishandling of shuffle problems can result in Skew.
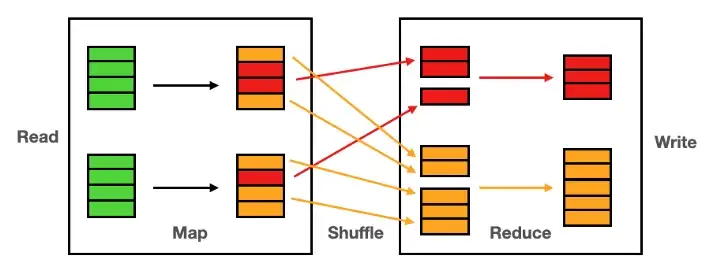
Figure 3: Shuffling Process (Image by Author).
Some approaches which can be used in order to reduce the amount of shuffling are:
- Instantiating fewer and larger workers (therefore reducing network IO overheads).
- Prefilter data to reduce its size before shuffling.
- Denormalize the datasets involved.
- Prefer using Solid State Drives over Hard Disk Drives for faster execution.
- When working with small tables, Broadcast Hash Join the smaller table. For big tables use instead SortMergeJoin (Broadcast Hash Join can lead to Out Of Memory issues with big tables).
Storage
Storage issues arise when data is stored on disk in a non-optimal way. Issues related with storage can potentially cause excessive Shuffle. Three of the main problems associated with Storage are: Tiny Files, Scanning and Schemas.
- Tiny Files: handling partition files less than 128 MB.
- Scanning: when scanning directories we could either have a long list of files in a single directory or in the case of highly partitioned datasets multiple levels folders. In order to reduce the amount of scanning, we can register it as a table.
- Schema: depending on the file format used there can be different schema issues. For example, using JSON and CSV the whole data needs to be read to infer data types. For Parquet instead just a single file read is needed, but the whole list of Parquet files needs to be read if we need to handle possible schema changes over time. In order to improve performances, it could then help to provide schema definitions in advance.
Serialization
Serialization encompasses all the problems associated with the distribution of code across clusters (the code is serialized, sent to the executors, and then deserialized).
In the case of Python, this process can even be more complicated since the code has to be pickled and an instance of the Python interpreter has to be allocated to each executor.
Serialization issues can arise when integrating codebases with legacy systems (e.g. Hadoop), 3rd party libraries, and custom frameworks. One key approach we can take to reduce serialization issues is avoiding using UDFs or Vectorized UDFs (which act like a black box for the Catalyst Optimizer).
Conclusion
Even with the latest release of Apache Spark 3, Spark Optimization remains one of the core areas in which practitioners’ expertise and domain knowledge are fundamental in order to successfully make the best use of Spark capabilities. As part of this article, have been covered some of the key problems which can be encountered in a Spark project, although these problems can in some circumstances be highly connected to each other therefore making it difficult to trace down the main root cause.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
