Contents

(Image Reproduced from https://imgur.com/gallery/OVvOuYZ)
Reinforcement Learning for anyone: Open AI Gym and Ray
A practical introduction to creating and optimizing Reinforcement Learning agents using Open AI Gym and Ray Python libraries
Introduction
Open AI Gym is an open-source interface for typical Reinforcement Learning (RL) tasks. Using Open AI Gym can, therefore, become really easy to get started with Reinforcement Learning since we are already provided with a wide variety of different environments and agents. All we have been left to do is to code up different algorithms and test them in order to make our agent learn how to accomplish in the best possible way different tasks (as we will see later, this can easily be done using Ray). Additionally, Gym is also compatible with other Python libraries such as Tensorflow or PyTorch, making therefore easy to create Deep Reinforcement Learning models.
Some examples of the different environments and agents provided in Open AI Gym are: Atari Games, Robotic Tasks, Control Systems, etc…

Figure 1: Atari Game Example [1]
If you are interested in finding out more about the theory behind the main concepts of Reinforcement Learning, additional information is available in my previous article.
Open AI Gym
In this section, we are now going to walk through some of the basics of the Open AI Gym library. First of all, we can easily install the library by using:
pip install gym
Once installed the library, we can then go on and instantiate an environment. For this example, we will use Lunar Lander. In this scenario, our objective is to make our agent learn to correctly land their spaceship between two flags (our landing pad). The more precisely the agent will be able to land and the greater will be the overall reward he will be able to achieve. The agent is able to choose any of the following four actions at any point in time in order to accomplish this goal: fire left engine, fire right engine, fire down the engine and do nothing.
In order to quickly visualise this scenario, let’s instantiate the environment and make our agent take iteratively a random action sampled from the environment (Figure 2).
import gymenv = gym.make("LunarLander-v2")
env.reset() # Instantiate enviroment with default parameters
for step in range(300):
env.render() # Show agent actions on screen
env.step(env.action\_space.sample()) # Sample random action
env.close()
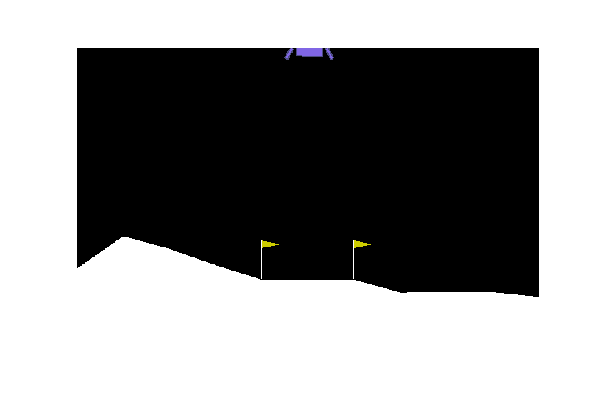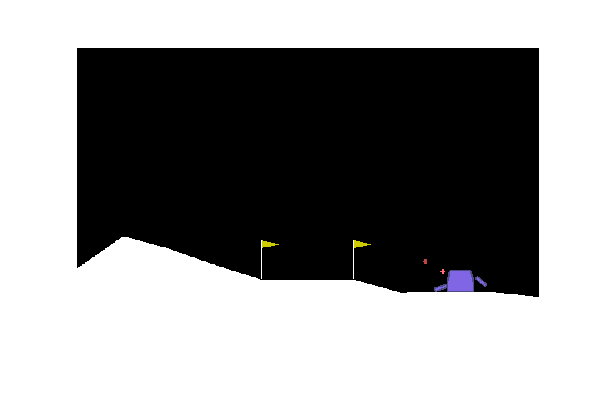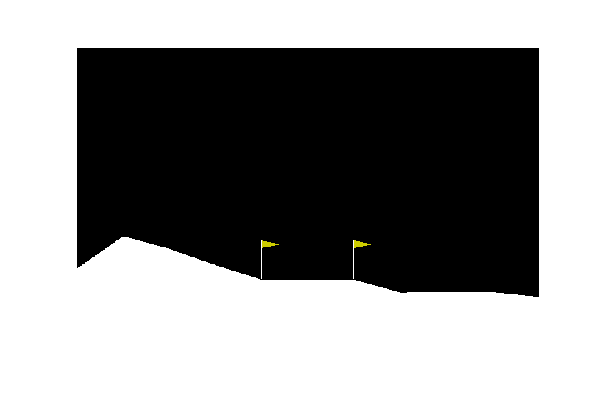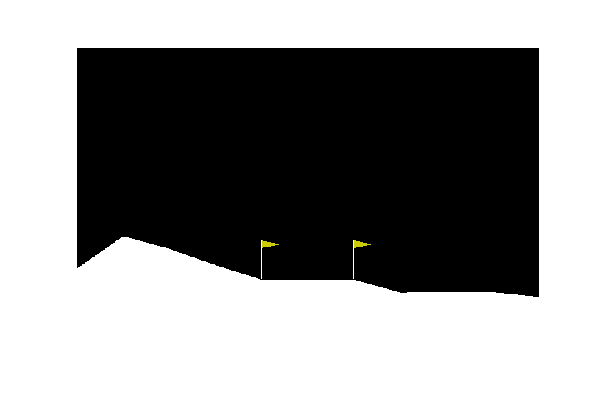
Figure 2: Agent Performing Random Actions
In order to improve our agent performances, we can then make use of the information’s returned by the step function:
- observation = information about the environment after performing an action (e.g. board position in a board game, pixel coordinates, etc…).
- reward = a quantitative representation of how positive was our previous action (the greater the better).
- done = is a boolean value showing if we reached the last iteration available (eg. we achieved our goal, our we run out of the maximum steps available to us).
- info = debugging utilities.
Making use of these pieces of information and a learning algorithm (e.g. Q-Learning, SARSA or Deep Reinforcement Learning) we will then be able to quickly solve a large number of problems in different environments.
Ray
Ray [2] is an open-source Python framework for multiprocessing which provides as part of its infostructure also a Reinforcement Learning library (RLlib) and a Hyperparameter Optimization library (Tune) in order create Reinforcement Learning models at scale.
In our previous example, using Open AI Gym was possible to easily create environments and agents, Ray will instead help us in making easier to test and optimise different learning algorithms for our agents.
Ray can be easily installed for Linux users using the following command:
pip install ray
For Windows users is although not yet provided full support and it might be necessary to use a Windows Subsystem for Linux (or make use of free tools such as Google Colab!).
Deep Q Learning Example
Now that we have successfully introduced Gym and Ray, we are ready to tackle the Lunar Lander problem described before. All the code used for this article is additionally available on my Github profile. First of all, we need to import all the required libraries.
import ray
from ray import tune
from ray.rllib import agents
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
Successively, using Ray we can easily instantiate a Deep Q Network (DQN) architecture in order to train our agent. Deep Q Networks are used in order to easily scale Table Q Learning-based algorithms by replacing them with a neural network able to learn how to correctly estimate the Q Values (Function Approximation). In case you are interested in finding out more about this topic, I highly suggest you to give a look at “Reinforcement Learning: An Introduction” by Richard S. Sutton and Andrew G. Barto.
A full list of all the different algorithms available in Ray is available at this link.
In the run function, we can then set the maximum number of timesteps allowed and pass different configuration arguments in order to tailor our network. Finally, using the tune.grid() functionality we can additionally perform grid-search in order to improve some of our model hyperparameters on the fly (eg. gamma and rate of learning).
results = tune.run(
'DQN',
stop={
'timesteps\_total': 50000
},
config={
"env": 'LunarLander-v2',
"num\_workers": 3,
"gamma" : tune.grid\_search(\[0.999, 0.8\]),
"lr": tune.grid\_search(\[1e-2, 1e-3, 1e-4\]),
}
)
Once trained our agent, a data frame will be returned containing all the main training metrics (Figure 3) which we can then use in order to identify which combination of hyperparameters can lead to a greater reward for our agent.
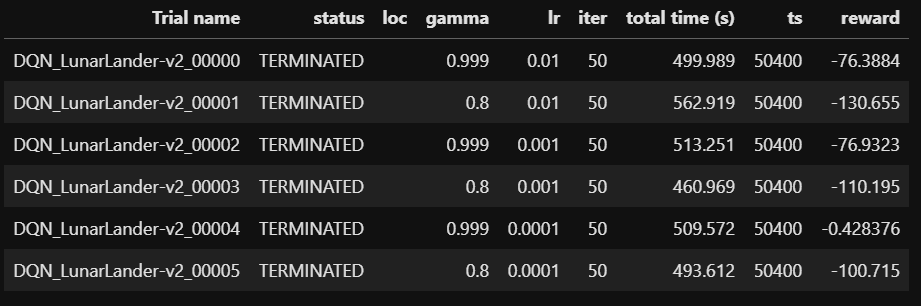
Figure 3: Summary of the training metrics
Making use of the returned data frame and the logged information, we can then easily visualise some key training metrics such us how using different parameters (eg. gamma and rate of learning values) can lead to different rewards over time (Figure 4).
Figure 4: Hyperparameters Optimization Report
Finally, using our identified best hyperparameters we can instantiate a new DQN model and log as a video the performance of our agent using ‘monitor’: True in our model configuration settings.
ray.init()config = {'gamma': 0.999,
'lr': 0.0001,
"n\_step": 1000,
'num\_workers': 3,
'monitor': True}
trainer2 = agents.dqn.DQNTrainer(env='LunarLander-v2', config=config)
results2 = trainer2.train()
As we can see in Figure 5, our agent successfully learnt how to complete our task!
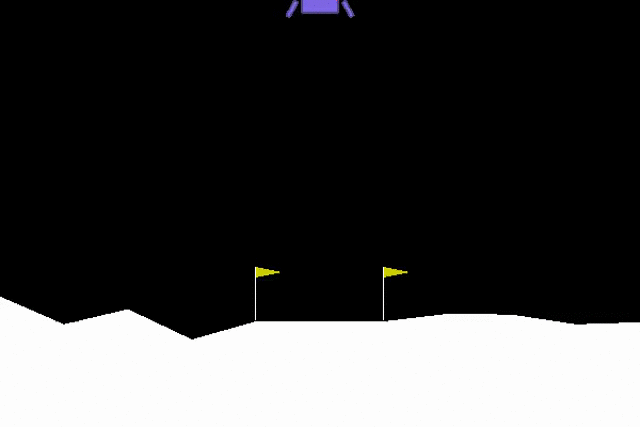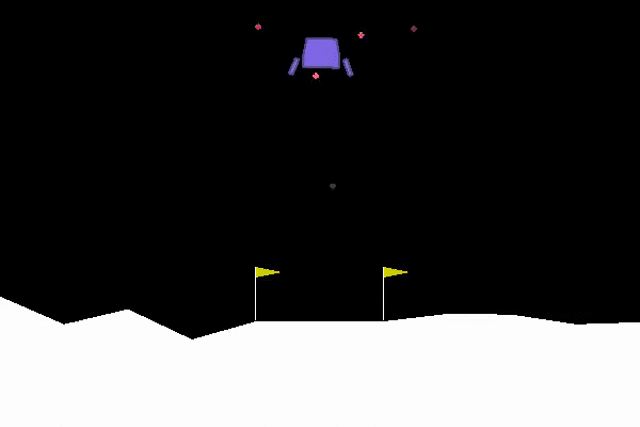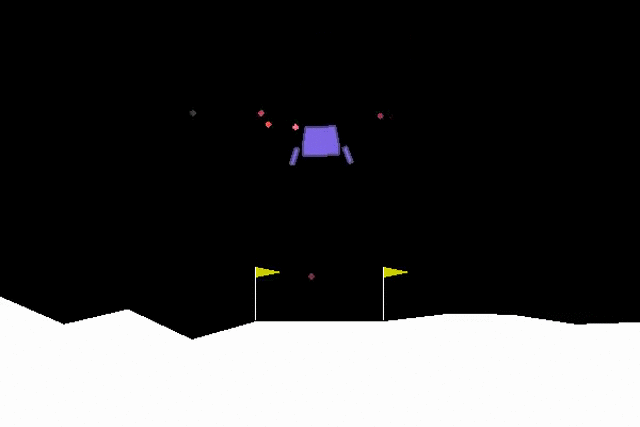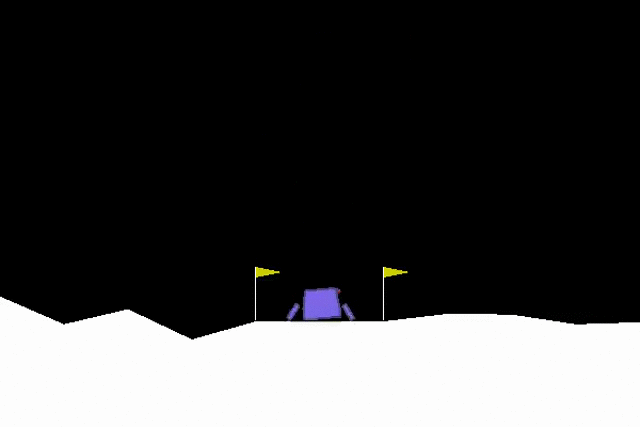
Figure 5: Trained Agent
I hope you enjoyed this article, thank you for reading!
Bibliography
[1] Fall 2018 CS498DL, Assignment 5: Deep Reinforcement Learning (University of Illinois at Urbana-Champaign), SVETLANA LAZEBNIK. Accessed at: http://slazebni.cs.illinois.edu/fall18/assignment5.html
[2] PyPI: Ray: A system for parallel and distributed Python that unifies the ML ecosystem. Accessed at: https://pypi.org/project/ray/
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
