Contents
 (Source: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html)
(Source: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html)
AI Differential Privacy and Federated Learning
Use of Artificial Intelligence on users sensitive data has recently raised numerous concerns. Differential Privacy and Federated Learning is the solution now proposed to this problem by companies such as Google and Apple.
Introduction
Sensitive data is collected every day in different forms (eg. hospital medical records, mobile phones activities records, etc…). Once the data is collected, is then preprocessed to become fully anonymous and finally made available to companies and research communities to be analyzed.
Making a dataset anonymous prevents anyone to be fully able to reverse engineering the data to its original form just making use of the dataset.
Although, the data contained in a dataset can be also available in any other form on the web. Reverse engineering of the original data can then become much easier by comparing different sources of the same data using mathematical statistical methods. In this way, the privacy of the people who gave their data can be compromised.
As an example, Netflix in 2007 released a dataset containing their user ratings for a public competition. The dataset had been fully anonymized prior to the lunch of the competition so that not to include any private information. Researchers successively tried to test the privacy security of this dataset and successfully managed to recover up to 99% of the removed personal information [1]. It was possible to achieve this result by comparing the data provided by Netflix with other information publicly available on IMDB.
Making use of techniques such as Differential Privacy and Federated Learning can drastically decrease this risk.
Differential Privacy
Differential Privacy enables us to quantify the level of privacy of a database. This can help us to experiment with different approaches in order to identify which is best to preserve the user’s privacy. By knowing our data privacy level we can then quantify the likelihood that someone might be able to leak sensitive information from the dataset and how much information can be leaked at most.
The definition of differential privacy given by Cynthia Dwork is:
Differential Privacy describes a promise, made by a data holder, or curator, to a data subject, and the promise is like this:
“You will not be affected, adversely or otherwise, by allowing your data to be used in any study or analysis, no matter what other studies, data sets, or information sources, are available”.
— Cynthia Dwork
One technique used by Differential Privacy to protect individuals privacy is to add noise in the data. The two main differential privacy methods are Local differential privacy and Global differential privacy.
- Local differential privacy = the noise is added to each individual data point in the dataset (either by a dataset curator once the dataset is formed or by the individuals itself before making their data available to the curator).
- Global differential privacy = the noise necessary to protect the individual’s privacy is added at the output of the query of the dataset.
Generally, global differential privacy can lead to more accurate results compared to local differential privacy, while keeping the same privacy level. On the other hand, when using global differential privacy, the people donating their data need to trust the dataset curator to add the necessary noise to preserve their privacy.
Typically two types of noise can be used when implementing differential privacy: Gaussian and Laplacian (Figure 1).
![Figure 1: Gaussian and Laplacian distributions [2]](https://cdn-images-1.medium.com/max/5204/1*B7XeRS6I7-wQIHfobzVDxQ.png)
Figure 1: Gaussian and Laplacian distributions [2]
In order to decide the amount of noise necessary to add on a dataset to make it privacy secure, the formal definition of Differential Privacy (Figure 2) is used.
![Figure 2: Differential Privacy Definition [3]](https://cdn-images-1.medium.com/max/2000/1*R8bT-N53FibRsa3GSL3C3Q.png)
Figure 2: Differential Privacy Definition [3]
In Figure 2, A represents a randomized algorithm that takes a dataset as an input, the datasets D1 and D2 differ by just one element and epsilon (ɛ) is a positive real number. Epsilon is used as a parameter to determine the amount of noise necessary.
Federated Learning
Machine Learning models which make use of a large amount of data are traditionally trained using online servers. Companies like Google and Apple used to take the data records activity of the users of their mobile devices and then store them in their cloud services to create a centralized Machine Learning model able to improve the performances of their mobile services.
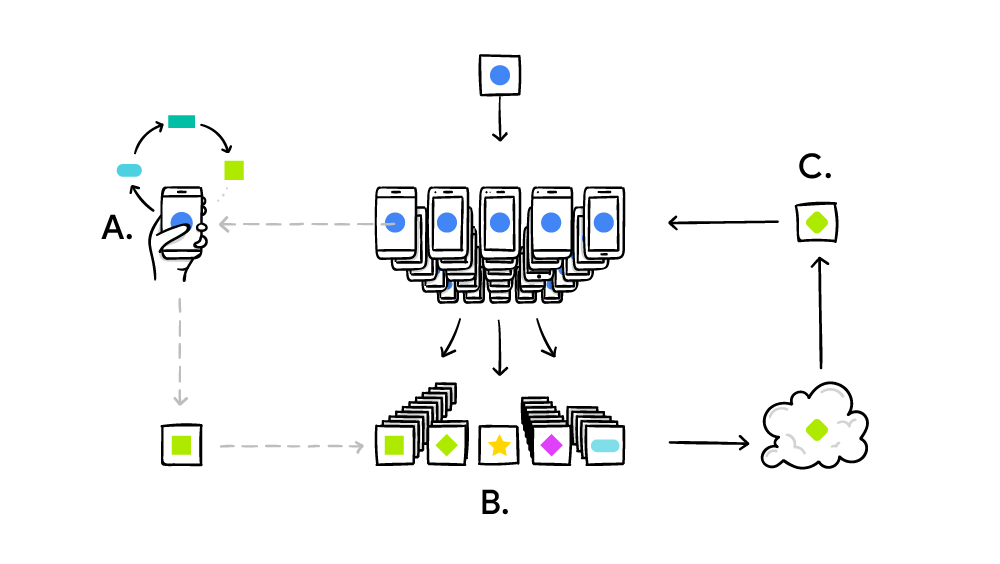
Nowadays, these big companies are moving instead towards using a decentralized model approach called Federated Learning. Using Federated Learning, the Machine Learning model is trained on the data source and its output is then moved on the cloud for further analysis. This means that companies like Google and Apple no longer need to access their user’s data to improve their services but instead can just use the output of the Machine Learning model trained locally (without breaking the user privacy).
Furthermore, because these models are trained locally can offer a more personalized experience to the end user (Figure 3).
A definition of Federated Learning can be:
- Federated Learning = a technique for training Machine Learning models on data to which we don’t have access. The dataset we use to train a model is distributed among a large number of resources.
![Figure 3: Federated Learning in action [4]](https://cdn-images-1.medium.com/max/2954/1*qO-0KDini9MuEKuic3iO-A.png)
Figure 3: Federated Learning in action [4]
Companies like Google specified that these types of local Machine Learning training are designed to just take place when the end device is: not used by the user, charging and has a wifi connection. In this way, the overall performance of the device is not affected.
Some examples of Federated Learning in action on smartphone devices can be: personalized word suggestions using the Gboard on Android, Gmail, and the Google search engine.
Google AI provided several examples of how Google makes use of Federated Learning and how does it work, these can be available here and here.
Conclusion
If you would like to find out more about these topics I vividly suggest you to enroll in the free Secure and Private AI course offered by Udacity. Other valuable resources to gain a better mathematical background can be these two publications [5, 6].
Bibliography
[1] Robust De-anonymization of Large Datasets (How to Break Anonymity of the Netflix Prize Dataset). Arvind Narayanan and Vitaly Shmatikov, The University of Texas at Austin. Accessed at: https://arxiv.org/pdf/cs/0610105.pdf
[2] Texture Segmentation Using Laplace Distribution-Based Wavelet-Domain Hidden Markov Tree Models. Yulong Qiao and Ganchao Zhao, MDPI. Accessed at: https://www.mdpi.com/1099-4300/18/11/384/html
[3] Differential Privacy, Wikipedia. Accessed at: https://en.wikipedia.org/wiki/Differential_privacy
[4] Differentially Private Federated Learning: A Client Level Perspective. Robin Geyer, Tassilo Klein, and Moin Nabi. Accessed at: https://medium.com/sap-machine-learning-research/client-sided-differential-privacy-preserving-federated-learning-1fab5242d31b
[5] Differential Privacy and Machine Learning: a Survey and Review. Zhanglong Ji, Zachary C. Lipton, Charles Elkan. Accessed at: https://arxiv.org/pdf/1412.7584.pdf
[6] Deep Learning with Differential Privacy. Martín Abadi, Andy Chu, Ian Goodfellow et al. Accessed at: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/45428.pdf
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
