Contents
Photo by Flex Point Security on Unsplash
Artificial Intelligence for Cybersecurity
A guide through some of the key applications of AI in order to enhance cybersecurity systems.
Introduction
One of the most promising applications of Artificial Intelligence (AI) is Cybersecurity. In fact, managing the security of large distributed systems can easily become an exponentially complicated task considering all the possible different scenarios an adversarial entity could try to use to take advantage of the security infrastructure in place. AI systems, on the other hand, can be particularly useful when trying to identify unusual patterns in large amounts of logs of data (e.g. anomaly detection, fraud classification, etc.).
There are 3 main ways AI models can be added to a security system, depending on the level of automation desired:
- Insights Generation: analyze the data to discover hidden patterns which can be used by decision-makers in order to react to anomalies.
- Recommendations: the model discovers patterns in the data and provides recommendations on what should be best to do to a security specialist.
- Autonomous mitigation: the model discovers patterns and tries to automatically solve problems without needing humans authorization.
These types of models can then be used at any of the 3 key stages of the security lifecycle (Prevention -> Detection -> Response). For example, in order to prevent security breaches in the first place, AI could be used to scan the organization source code for potential bugs, model potential threats, or address data loss concerns.
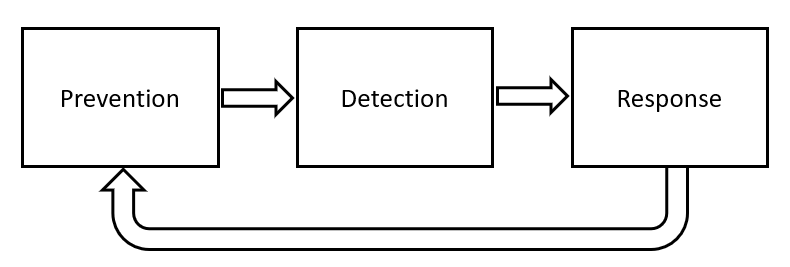
Figure 1: Cybersecurity Systems Lifecycle (Image by Author).
One of the key advantages of using AI security systems is that the models can be automatically scheduled to retrain as new logs are stored making, therefore, easier to identify new threats, rather than having to rely on engineers to identify and address every possible future edge case. Additionally, using autonomous mitigation approaches can also lead to much faster responses to potential attacks (although, this would lead to humans having less control over the system, which could be problematic in the case of false positive/negative predictions).
Security systems are typically designed in order to maximize 3 different criteria: Confidentiality, Integrity and Availability (CIA). Although tradeoffs are usually required in order to maximize more than one of these 3 objectives at once (e.g. in order to upgrade the integrity system it might be necessary to make the service unavailable for a few hours, therefore reducing availability). Different organizations can then have different priorities on which of these 3 objectives to prioritize and why AI should be embedded (e.g. scale, velocity, improving accuracy).
Techniques
Supervised Learning
When working with supervised learning problems, we are provided with a dataset already labelled (we have some past data about a phenomenon and its resulting outcome). In this scenario, we can be either interested to learn how to predict to which class a new data point might belong to (classification) or to assign it a numerical value from a continuous spectrum (regression).
Regression problems could be used in cybersecurity for example in order to try to predict how many devices could have been corrupted by a cybersecurity attack or quantify the level of damage due to a security attack. An example of a classification problem could instead be trying to predict if a login attempt is genuine or not (based on factors such as location, time, machine, etc.).
When working with classification problems it can be extremely important to make sure to have a balanced number of examples for each possible output class. For example, when classifying login attempts we will probably have many more examples of genuine logins rather than fraudulent logins. In order to achieve good accuracy, an AI model could then automatically become biased to predict login attempts are always genuine. In order to try to avoid these kinds of problems, techniques such as oversampling/under-sampling and penalization of the majority class are typically used. Additionally, in unbalanced classification problems, metrics such as the Receiver operating characteristic (ROC) curve and precision/recall are typically preferred to metrics like accuracy since they automatically take into account the imbalance in cases between the different classes.
Unsupervised Learning
When working with unsupervised learning problems, we are provided with a dataset, but no corresponding labels. Three example applications of how unsupervised learning can be used in cybersecurity systems are: Word Embeddings, Anomaly Detection and Synthetic Data Generation.
Word Embeddings are typically used in order to convert text data into a numerical format suitable for being processed by an AI model. In Cybersecurity this could for example be used in order to create Data Loss Prevention models. Data Loss Prevention solutions are designed in order to check if any confidential information is being shared with an unauthorized party (e.g. a passport number being shared without permission) and makes, therefore, use of large amounts of embedded training text data.
Anomaly Detection techniques such as Isolation Forests and Variational Autoencoders can instead be used in a security system in order to identify any form of suspect activity in logs (e.g. a fraudulent transaction) and immediately alert the system.
Finally, Synthetic Data Generation techniques such as Generative Adversarial Networks (GANs) are typically used in order to generate statistically undistinguishable new data which can be used to train/test an AI model if we don’t have already available large quantities of data.
Conclusion
Overall, the use of AI in Cybersecurity systems can provide many different benefits, although the following points should definitively be taken into consideration:
- People trying to compromise your system might be using AI-based techniques as well.
- Not well implemented AI systems will likely perform worse than traditional cybersecurity approaches.
- After time, malicious agents could manage to understand what kind of inputs might trigger or not your AI model and then design a strategy to take advantage of it.
For example, a malicious agent could try to take advantage of an AI-based system by attempting to alter the AI model behavior. This could be done for instance by feeding a series of carefully designed data points in the model to try to understand a classifier decision boundary and then take advantage of the information gained to let through some malicious inputs without alerting the system. Alternatively, the malicious agent could also try to directly modify the training data used to prepare the model in the first place to affect its accuracy (Data Poisoning Attack).
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
