Contents
Photo by Artem Gavrysh on Unsplash
Getting started with Feature Stores
An Introduction to what are Feature Stores and how can they be used in order to streamline your Machine Learning processes
Introduction
Creating Machine Learning models able to perform reliably in production, can be a very difficult process. These models can in fact only be as good as the data it is used to train them. Therefore, being able to create a process capable to accurately pre-process all the incoming data and structure it in the best way possible to train a model, can play a key role in the long term success of a project.
Some examples of techniques commonly used by Data Scientists and Data Engineers in order to pre-process data to be used in a Machine Learning model are:
- Feature Engineering: fixing inconsistencies in the data and creating new features by combining/diving existing ones.
- Feature Extraction: reducing a dataset dimensionality using techniques such as PCA, t-SNE, etc…
- Feature Selection: reducing the number of features in a dataset by eliminating features which carries less information or which add just noise in our analysis.
Some of the key benefits of pre-processing thoroughly our data are:
- Reducing the risk of overfitting.
- Speeding up training times.
- Reduced need to perform Hyperparameters Optimization.
- Improved Data Visualization.
Therefore, data pre-processing can in some cases ends up being a lengthy process in order to make sure that our data is in the best format as possible and that all the different edge cases are taken into account (especially when new data is ingested in the pipeline).
As more organizations are starting to make use of Machine Learning processes in many different areas of their business, it could then be really important to try to avoid any form of duplicated work when it comes to pre-processing data which could then be used by different teams and for different models within an organization. In order to make sure any duplicated work across the business is eliminated and to gain a better insight of how data is used within an organization, the Feature Store was created.
Feature Store for ML
Feature Stores are a data management layer designed for Machine Learning processes. Feature Stores act therefore as a central repository within a company with all the different features which have ever been created to be used for Data Analysis and Machine Learning.
In addition to just storing all the different features, Feature Stores have also been designed to completely automate the ingestion of new data (by automatically applying the necessary data pre-processing steps) and keep track of any changes in their distribution. In this way, Feature Stores can be used for both storing and transforming features so that to make easier for Data Scientist to find any feature they might need and use them whiteout having to worry about maintenance (features are automatically updated for future predictions and a history of any changes can be retrieved if needed).
Finally, Feature Stores have been designed in order to support both batch and online types of applications. For batch applications, it might be necessary to store a large amount of data (depending on how frequently the batches are updated), for online applications instead achieving low latency is usually the main priority. In order to achieve this, Feature Stores, are commonly designed as some form of dual-database (e.g. SQL database to store batch data and a key-value store for fast processing of online data).
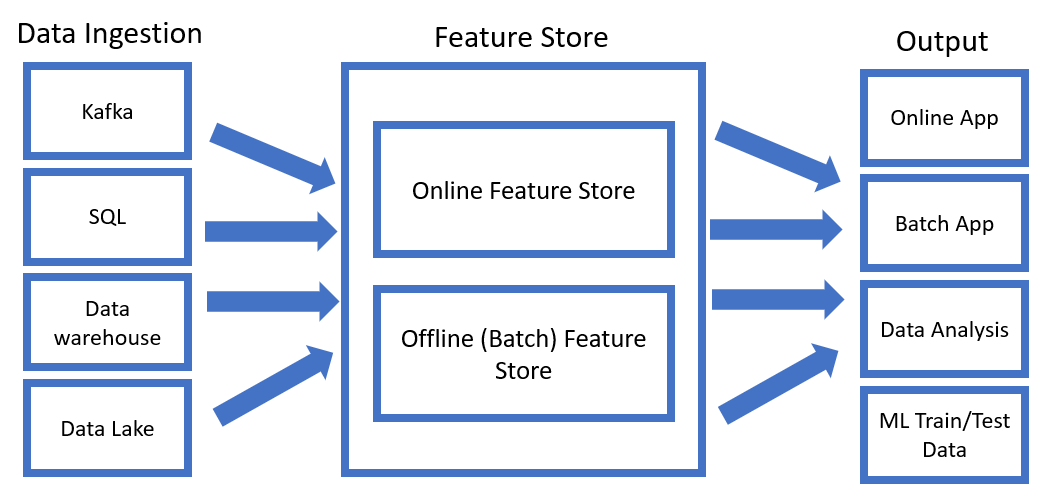 Figure 1: Example Feature Store (Image by Author).
Figure 1: Example Feature Store (Image by Author).
Making use of Feature Stores can therefore lead to many different benefits for an organization such as:
- Automated Data Preparation: once new raw data is added, features can be automatically updated (e.g. if we have a preprocessed feature that used linear regression to impute missing values, this same transformation can be applied once new data is added to the feature).
- Improved Model Training/Re-training: having a history of how features change over time, can help us quickly retrain our model as new data comes in, and to adequately update our test data to reflect how the real world environment changed since our last training.
- Improved Model Monitoring after deployment: as new data is stored, checks can be added in order to see if there have been any drastic changes in the distribution of each feature and create alerts to then retrain our model.
- Faster time to market for new models: data science teams can spend less time on pre-processing data and more on experimenting and creating the best possible model.
- Features sharing between teams: once a feature has been created and documented, it can then be automatically reused for other projects in the future.
- Ensuring the use of best MLOps practices: Machine Learning Operations (MLOps) is a set of best practices designed in order to make sure Machine Learning models can be created as fast as possible while making them as easy as possible to maintain and govern. Using Feature Stores can greatly help us in meeting both objectives.
- Complete governance of your data: using Feature Stores make it easier to see how data is processed throughout time by an organization and to quickly act in case of any regulatory concern.
Creating a Feature Store
During the past few years, different open-source and enterprise solutions have been ideated in order to facilitate the adoption of Feature Stores. Two of the most common open source solutions are Feast and Hopsworks. For enterprise users instead, Feature Stores capabilities have been added to cloud services such as GCP Vertex AI, AWS Sagemaker and Databricks.
If you are unsure about which platform to use for your Feature Store, different tools such as Feature Store Comparison are available in order to provide you a breakdown of the differences between the different providers.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
